Introduction
ElasticSearch est un moteur de recherche puissant, mais pour en tirer pleinement parti des optimisations sont nécessaires à plusieurs niveaux: mémoire, index, requêtes, cycle de vie des index, surveillance et suivi.
Dans cet article, nous allons étudier des exemples concrets de configuration pour optimiser les performances d’ElasticSearch en production.
Choisir les bons paramètres pour la mémoire
JVM
ElasticSearch est écrit en Java et se repose donc sur la JVM (Java Virtual Machine) pour son exécution. Une mauvaise gestion de la mémoire peut entraîner des ralentissements, voire des échecs. Voici un exemple de configuration recommandée pour allouer la mémoire à la JVM dans le fichier jvm.options :
# Taille de la mémoire JVM (maximale et minimale) -Xms16g -Xmx16g
Dans cet exemple, nous allouons 16 Go de mémoire à la JVM. Il est recommandé de ne pas dépasser la moitié de la RAM totale disponible, avec un maximum de 32 Go pour éviter des problèmes liés à l’optimisation de la JVM et de son ramasse-miettes (Garbage collector).
Désactiver la partition d’échange (swap)
La plupart des systèmes d’exploitation essaient d’utiliser autant de mémoire que possible pour les caches du système de fichiers. Le système transfère également la mémoire non utilisée vers les disques. Cela peut entraîner le transfert de la mémoire de la JVM d’ElasticSearch sur le disque et provoquer des ralentissements des passages du ramasse-miettes.
Dans un système distribué et résilient, il est préférable de laisser le système d’exploitation tuer le processus ElasticSearch.
sudo swapoff -a
Sur les systèmes Linux, il faudra rendre ce paramètre permanent en modifiant /etc/fstab.
Index buffer size
Lors d’un import en masse de données, il est recommandé d’augmenter la taille de la mémoire tampon allouée aux nouveaux documents indexés :
indices.memory.index_buffer_size: 50%
Une fois l’ingestion finie, ce paramètre doit être remis à sa valeur initiale (10%).
Optimiser la configuration des index
Nombre de shards
Le nombre de shards par défaut est 1, ce qui peut être trop peu selon le type et la volumétrie des données. Par exemple, si vous avez un index de grande taille (200GB), vous devez augmenter le nombre de shards pour améliorer l’efficacité et réduire la taille des shards.
Visez entre 10GB et 50GB par shard. Des shards trop gros sont longs à parcourir et à déplacer entre deux machines. Des shards trop petits vont considérablement augmenter le nombre de shards total (1000 par machine maximum).
En utilisant l’API ElasticSearch nous définissons le nombre de shards lors de la création de l’index :
PUT /mon_index
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 1
}
}
Dans cet exemple, nous définissons assez de shards et de réplicas pour assurer le stockage de nos 200GB et leur redondance, tout en respectant les recommandations.
Mapping des index
Définir un bon mapping des champs peut réduire l’empreinte mémoire d’un index et améliorer la performance des recherches. Par exemple, si vous avez un champ de type text que vous ne souhaitez pas indexer (comme un champ de description très long), vous devez le désactiver dans le mapping.
De manière générale, n’indexez pas une information ne servant pas à la recherche. Le champ sera quand même consultable lors de la lecture des documents, car il fait partie du `_source`.
Le « dynamic mapping » d’ElasticSearch est intéressant quand on débute, car il détecte les types des champs inconnus et leur assigne automatiquement un mapping. En revanche, c’est un problème si des nouveaux champs arrivent tous les jours dans le système, cela peut entraîner un phénomène appelé « mapping explosion ».
Création de l’index avec l’API ElasticSearch :
PUT /mon_index
{
"mappings": {
"dynamic": false,
"properties": {
"description": {
"type": "text",
"index": false
}
}
}
}
Cela désactive les mappings automatiques et l’indexation du champ description, réduisant ainsi la consommation mémoire et améliorant les performances des requêtes.
Optimisation des segments
Les segments sont des morceaux d’un shard qui contiennent des documents. Trop de petits segments peuvent ralentir les requêtes. Voici un exemple de configuration de la politique de fusion (merge policy) pour réduire le nombre de segments en les fusionnant plus souvent :
PUT /mon_index/_settings
{
"settings": {
"index.merge.policy.max_merged_segment": "5gb",
"index.merge.scheduler.max_thread_count": 1
}
}
Ici, nous spécifions que les segments ne doivent pas dépasser 5 Go et nous limitons le nombre de threads utilisés pour leur fusion.
Attention cependant, ne cherchez pas à optimiser les index en cours d’écriture. Cette optimisation doit être réalisée sur les index en lecture seule.
Optimiser les requêtes et les recherches
Utilisation des filtres
Lorsque vous exécutez des recherches filtrées, utilisez des filtres plutôt que des requêtes pour améliorer la performance. Les filtres sont plus rapides car ils ne calculent pas de scores et génèrent du cache.
Exemple d’utilisation d’un filtre dans une requête ‘bool’ :
POST /mon_index/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "status": "actif" } },
{ "range": { "date": { "gte": "2023-01-01" } } }
]
}
}
}
Ici, nous appliquons un filtre sur le champ status et une plage de dates, ce qui rend la recherche plus rapide qu’une requête classique.
Caching des requêtes gourmandes
Lors d’une requête sur un ou plusieurs index, chaque shard exécute sa recherche localement. Ils retournent ensuite le résultat au nœud qui coordonne la requête. Le cache des requêtes permet de garder en mémoire les résultats des requêtes fréquentes au niveau de chaque shard.
Même si les paramètres de base sont bien définis, il peut s’avérer nécessaire de les modifier si la taille du cache par défaut n’est pas assez grande (par défaut 1% de la heap size).
indices.requests.cache.size: 2%
Le cache est invalidé lors d’un refresh de l’index, c’est à dire lors d’une écriture sur le disque de la mémoire tampon de l’index. Un index en lecture seule aura donc son cache permanent. Les index en écriture fréquente verront leur cache expirer souvent, ce qui est tout à fait normal.
Suivi et surveillance en production
Surveillance de la santé du cluster
Quelques commandes sont à connaître pour avoir une vue globale de la santé du cluster et de la répartition de la charge.
GET _cluster/health
C’est la première commande à tester. Elle retourne un état global de la santé du cluster avec des métriques de haut niveau. Avec un peu d’expérience les résultats de cette commande guideront votre intuition lors d’une recherche de causes de pannes.
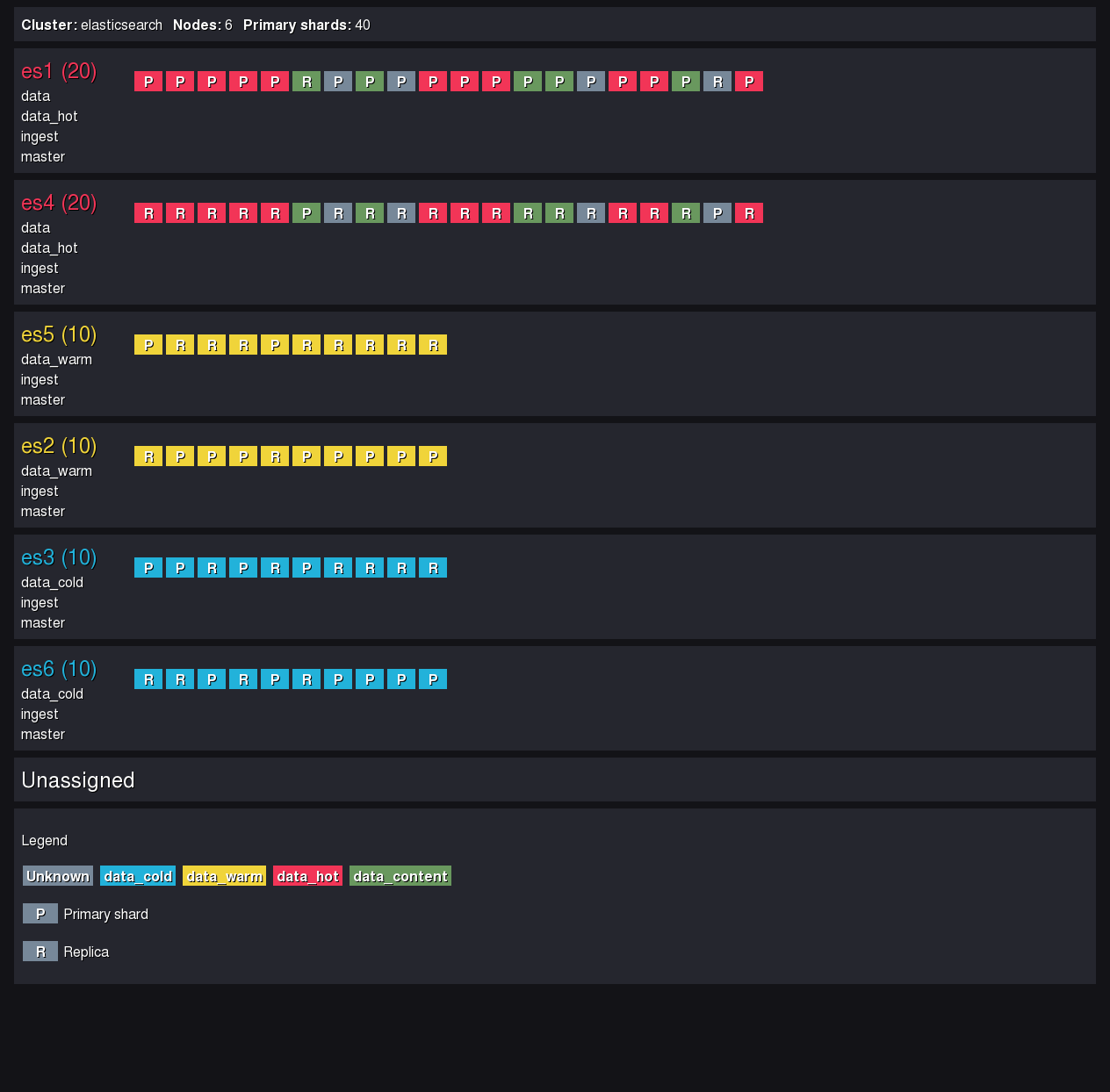
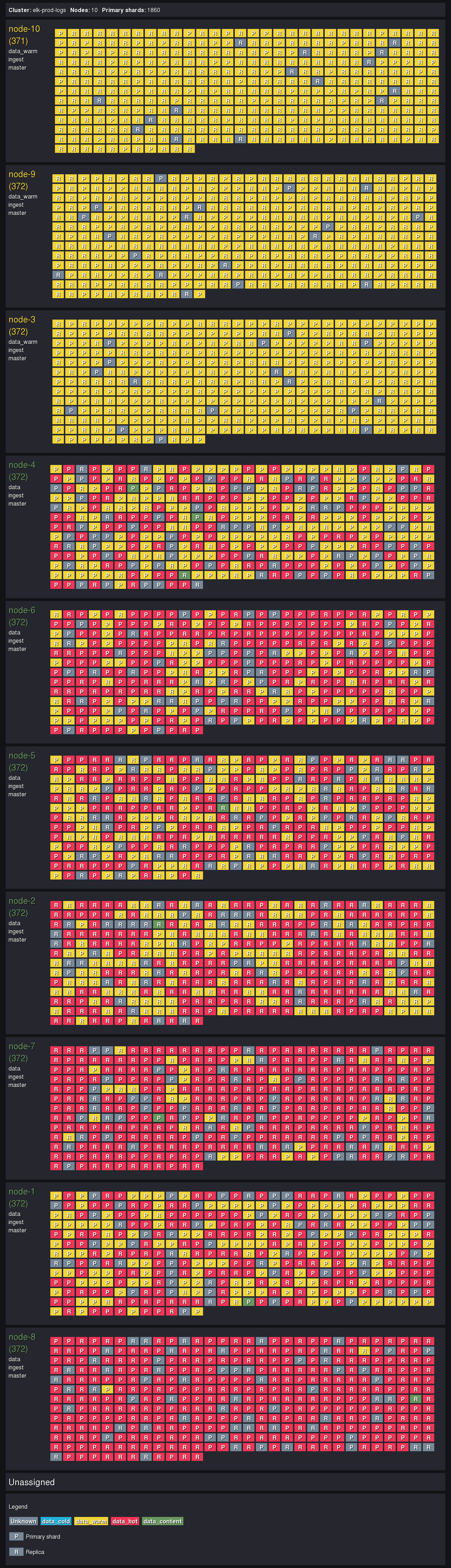
L’allocation des shards :
GET _cat/allocation?v
Cette commande donne une vision globale de la répartition des données, et en un coup d’oeil nous pouvons déterminer si notre cluster est à l’équilibre.
Quelques options d’affichage rendent cette commande encore plus lisible :
GET _cat/allocation?v&h=node,shards,disk.used,disk.percent
Pour vérifier les tailles des shards, et s’assurer que les recommandations sont respectées, nous pouvons lister les shards triés en fonction de leur taille (décroissante).
GET _cat/shards?h=index,shard,prirep,node,store&s=store:desc
Si des shards sont trop gros (plus de 50GB), alors il faudra prendre une action (suppression, réindexation, …).
Métriques
Les métriques de vos machines ElasticSearch sont consultables dans les écrans de supervision de Kibana. Cependant, il est recommandé de ne pas stocker ces informations dans le cluster lui-même. Stockez ces données dans un autre cluster ElasticSearch dédié aux informations de monitoring.
Le déploiement d’agents ElasticSearch, ou directement de MetricBeat sur toutes les machines à monitorer est à réaliser pour que ces informations remontent.
Alertes
Configurez des alertes pour suivre des métriques critiques. Vous devez surveiller l’utilisation de la mémoire, la latence des requêtes ou la disponibilité des nœuds. Cela vous permet de réagir rapidement en cas de problème. Attention cependant à la licence ElasticSearch utilisée. Les sorties d’alertes ne sont pas les mêmes selon la licence choisie. Par exemple, il n’est pas possible d’envoyer un e-mail en license basic open-source.
Conclusion
Il est essentiel d’optimiser ElasticSearch pour garantir des performances élevées et une mise à l’échelle. En suivant ces bonnes pratiques et en appliquant les configurations recommandées, vous pouvez maximiser l’efficacité de votre cluster ElasticSearch. La surveillance continue est également un élément clé pour maintenir un système performant à long terme.