Description
La gestion d’une centaine de milliards de documents (données issues de logs applicatifs, équipements réseau, middlewares, etc.) s’avère coûteuse (machines, disques, espace de sauvegarde, etc.).
Pour alléger ce coût d’infrastructure nous devons distinguer les données brûlantes des données tièdes et froides (voir gelées). C’est ce que propose ElasticSearch avec l’ILM (Index Lifecycle Management). Nous vous proposons ainsi d’analyser sa mise en œuvre sur un cluster de production d’un de nos clients.
Les données considérées brûlantes doivent être exploitables dans des temps de réponse très courts, nous devons donc les placer sur des machines dimensionnées correctement. Les requêtes sur les données tièdes et froides n’ont pas besoin d’être aussi performantes, ces données peuvent donc automatiquement être déplacées vers des machines plus modestes grâce aux règles de rétention offertes par ILM.
Limitations des écrans dans Kibana et Cerebro
Kibana, l’interface graphique de la suite Elastic ne propose pas une vue synthétique de cette répartition. Nous pouvons obtenir cette information de répartition grâce à plusieurs requêtes, mais nous devons alors croiser les résultats, ce qui est fastidieux.
Cerebro, une interface graphique issue de la communauté open source, est excellent dans la visualisation de la répartition de la charge, mais ne propose pas cette visualisation au niveau du cycle de vie.
Même constat pour Elasticvue, qu’il s’agisse de sa version desktop, extension Chrome ou webapp.
Un moyen d’obtenir les informations souhaitées est donc de passer par l’API d’ElasticSearch.
Avec une première API nous pouvons obtenir les rôles des machines :
GET _nodes/settings?filter_path=nodes.*.roles,nodes.*.name
{
"nodes": {
"ECNRRDP2SUKmcu3s9qJgnA": {
"name": "es3",
"roles": [
"data_cold",
"ingest",
"master"
]
},
"NXZNCa_BQ_SE613oSnDf-g": {
"name": "es6",
"roles": [
"data_cold",
"ingest",
"master"
]
},
"jqmdwzdeQHG84601oQjpGw": {
"name": "es1",
"roles": [
"data",
"data_hot",
"ingest",
"master"
]
},
"4z2k13n8SZS4t2JmLielaQ": {
"name": "es4",
"roles": [
"data",
"data_hot",
"ingest",
"master"
]
},
"AFRMIIagRWK4Cu-ZhbLH2A": {
"name": "es5",
"roles": [
"data_warm",
"ingest",
"master"
]
},
"sxljzKF-Q1app0VSkVgTxg": {
"name": "es2",
"roles": [
"data_warm",
"ingest",
"master"
]
}
}
}
Puis avec une deuxième API nous pouvons récupérer le cycle de vie des indices (index au pluriel).
GET /*/_settings?filter_path=*.settings.index.routing.allocation.include,*.settings.index.uuid,*.settings.index.provided_name
{
".ds-my-index-1-2024.09.17-003772": {
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_hot"
}
}
},
"provided_name": ".ds-my-index-1-2024.09.17-003772",
"uuid": "HyELPU6oTpC_EfskAxP5BQ"
}
}
},
".ds-my-index-1-2024.09.17-003748": {
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_warm,data_hot"
}
}
},
"provided_name": ".ds-my-index-1-2024.09.17-003748",
"uuid": "QNC-Z2loT4SCKFb2-LJKAw"
}
}
},
".ds-my-index-1-2024.09.17-003714": {
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_cold,data_warm,data_hot"
}
}
},
"provided_name": ".ds-my-index-1-2024.09.17-003714",
"uuid": "zIP72E-qTBSfKbZdAYmFEQ"
}
}
},
[...]
}
Et avec une troisième API nous pouvons restituer le détails des blocs de données correspondant aux indices :
GET /_cat/shards?format=json&h=index,node,state,prirep,docs
[
{
"index": ".ds-my-index-1-2024.09.17-003848",
"node": "es1",
"state": "STARTED",
"prirep": "p",
"docs": "120"
},
{
"index": ".ds-my-index-1-2024.09.17-003848",
"node": "es4",
"state": "STARTED",
"prirep": "r",
"docs": "47"
},
{
"index": ".ds-my-index-1-2024.09.17-003828",
"node": "es5",
"state": "STARTED",
"prirep": "p",
"docs": "29"
},
{
"index": ".ds-my-index-1-2024.09.17-003828",
"node": "es2",
"state": "STARTED",
"prirep": "r",
"docs": "147"
},
[...]
]
En croisant les résultats de ces trois requêtes, nous pouvons donc savoir si un bloc de données d’un index « brûlant » est bien placé sur un noeud « brûlant ». Mais pour des milliers d’index, cela devient beaucoup plus laborieux.
Développement d’une solution de visualisation
Quelques lignes de JavaScript (64), d’HTML (80) et de CSS (118) plus tard et voici un aperçu d’un rapport réalisé sur un cluster ElasticSearch en local.
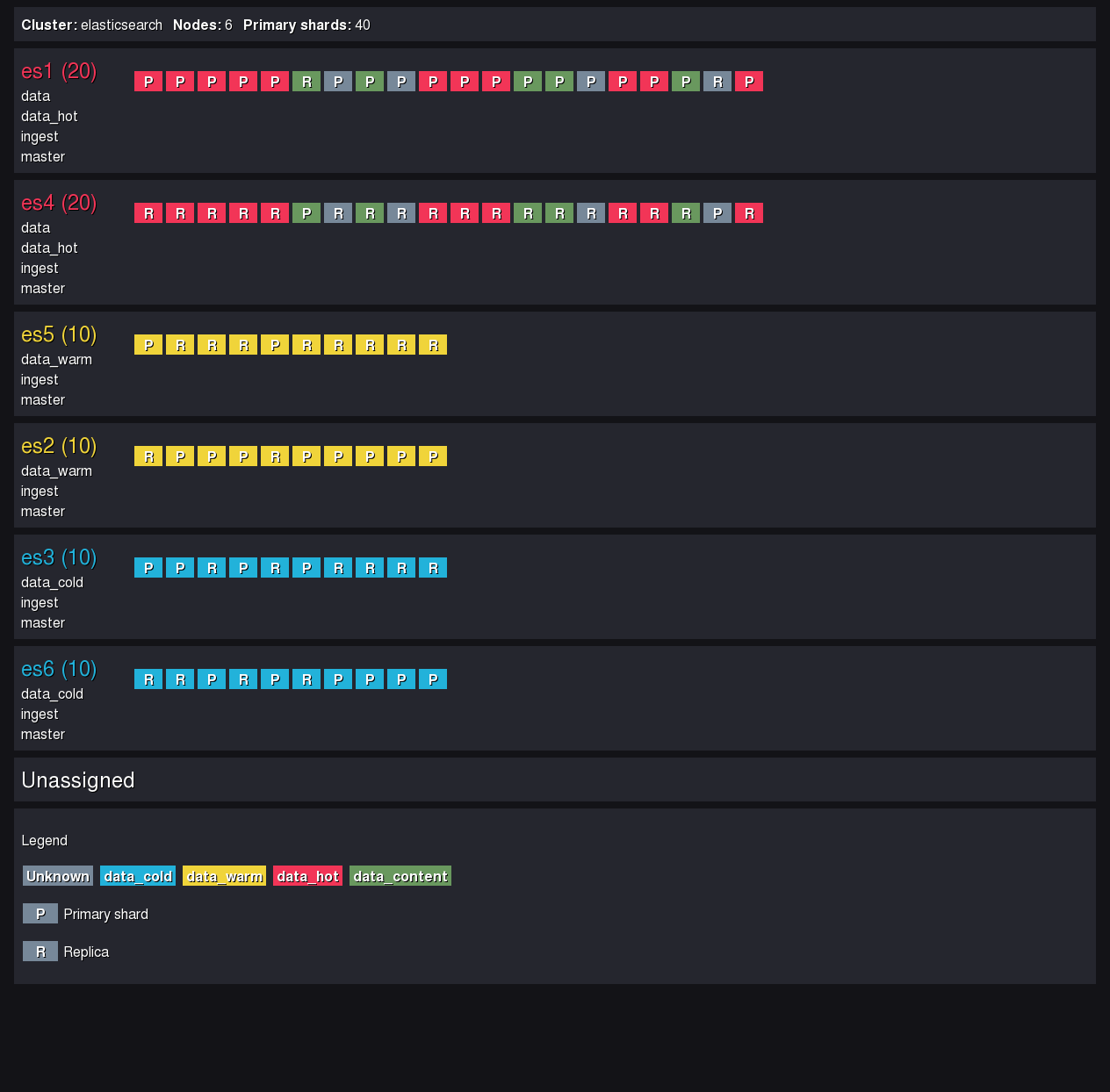
Résultat de l’analyse du cluster local
L’outil génère un fichier de rapport en format HTML, consultable depuis n’importe quel navigateur. Alors, en un coup d’œil on peut savoir si un bloc est à la bonne place.
Le code source est disponible sur Github.
Pour résumer ce que fait techniquement ce code source :
- Lancement des 3 requêtes précédemment étudiées
- Injection de ces données dans un moteur de template HTML
- Sauvegarde du résultat dans un fichier HTML
Premier rapport réalisé sur une infrastructure de production et analyse
Ensuite, nous avons intégré l’outil dans une chaîne d’intégration continue de Gitlab pour automatiser la génération des rapports. Nous pouvons ainsi désormais nous interfacer avec le cluster à analyser et donc générer un premier rapport.
Quelques données sur la taille du cluster :
- 10 machines ElasticSearch
- 110 milliards de documents
- 125 To de données stockées
- 25 000 événements par seconde
Le premier rapport montre une répartition de la charge logique comme ci-dessous :
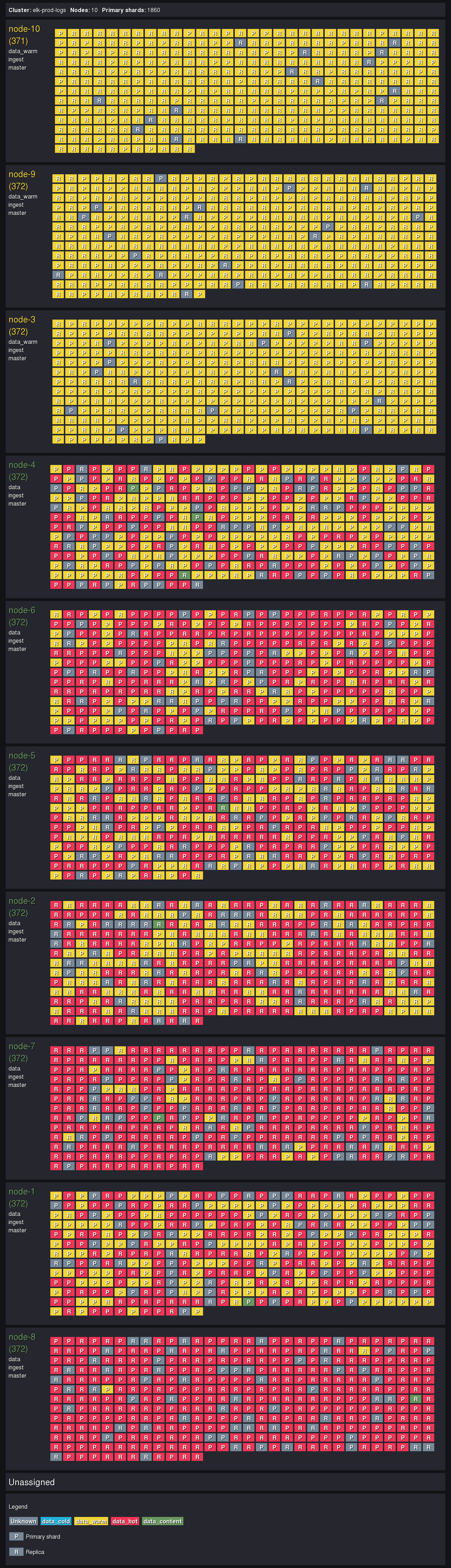
Résultat de l’analyse du cluster de production
Les nœuds ayant le rôle data_warm reçoivent bien les blocs data_warm. Les nœuds ayant le rôle data (tout les rôles) reçoivent tout type de blocs.
Cependant ce n’est pas encore optimisé pour réduire les coûts car :
- Il reste des blocs data_warm non alloués à des nœuds data_warm car ElasticSearch cherche l’équilibre en termes de nombre de blocs par machine.
- Aucun bloc de données froides n’apparaît car les règles de rétention ne définissent pas de phase « cold ». Des nœuds data_cold doivent être ajoutés au cluster.
- Il y a légèrement trop de données brûlantes en proportion, la durée de rétention en phase « hot » doit être revue à la baisse.
Evolution du cluster
Ainsi, après réflexions avec les équipes en charge de la maintenance du cluster, nous avons définit la cible à atteindre :
- 3 nœuds cold (à venir)
- 5 nœuds warm (node-3 node-9 node-10 node-1 node-2)
- 2 nœuds hot warm master (node-4 node-5)
- 3 nœuds hot ingest master content (node-6 node-7 node-8)
Les raisons de ces choix dépendent des caractéristiques des machines à disposition (CPU, disques, RAM).
Les mouvements de blocs vont être nombreux, et nous réfléchissons déjà à la procédure de migration afin de perturber au minimum le service. Il faut bien prendre en compte que l’espace disque pris par chaque bloc est de 50Go, et que chaque déplacement prend entre 30 minutes et 1 heure sur cette infrastructure réseau.
Nous avons ensuite planifié l’exécution de l’outil pour fournir un rapport tous les jours afin de suivre l’évolution de la répartition. Nous aurons donc un joli jeu de couleurs d’ici quelques semaines 