Rappels de quelques notions
Avant d’aborder le sujet de la HA (High Availability), il est utile de rappeler quelques principes qui vont être utilisés dans la suite de cet exposé.
RPO et RTO
Il existe plusieurs méthodes de sauvegarde d’une base de données PostgreSQL, chacune présentant des avantages et des inconvénients eu égard à la volumétrie des données, à la granularité des sauvegardes qu’on veut réaliser, à la cohérence des données sauvegardées, au transfert des données entre différentes versions de PostgreSQL et entre machines d’architectures différentes. Par ailleurs, on distingue deux types de sauvegardes : les sauvegardes logiques et les sauvegardes physiques.
Une sauvegarde logique consiste à archiver les commandes sql qui ont servi à générer la base et à les rejouer pour la restauration de celle-ci. Pour celà, il existe 2 commandes dans PostgreSQL : pg_dump et pg_dumpall. On trouvera plus de détails sur ces commandes dans la documentation de PostgreSQL https://www.postgresql.org/docs/10/backup.html.
Une sauvegarde physique ou sauvegarde au niveau du système de fichiers consiste à archiver les répertoires des données de la base en utilisant les commandes de copie ou d’archivage des fichiers du système d’exploitation : tar, cp, scp, rsync, … On peut aussi réaliser une “image gelée” (frozen snapshot) du volume contenant la base de données et ensuite copier entièrement le répertoire de données (pas seulement quelques parties) de l’image sur un périphérique de sauvegarde, puis de libérer l’image gelée.
Les objectifs d’une bonne procédure de sauvegarde sont exprimés par deux métriques :
- le RPO (Recovery Point Objective) : représente la quantité maximum de données qu’on peut tolérer de perdre suite à un incident de la base de données.
- le RTO (Recovery Time Objective) : représente la durée maximum d’une interruption de service qu’on peut tolérer, le temps de restaurer la base et la remettre en service.
L’objectif idéal étant que ces 2 paramètres soient nuls, PostgreSQL propose des approches qui permettent de s’en approcher. Elles sont basées sur la mise en oeuvre de l’archivage continu et la récupération d’un instantané (PITR : Point In Time Recovery).
Archivage continu et PITR
Cette approche est basée sur l’utilisation des journaux WAL (Write Ahead Log), appelés aussi journaux des transactions. Ils enregistrent chaque modification effectuée sur les fichiers de données des bases. Ils sont stockés dans le sous-répertoire pg_wal/ du répertoire des données du cluster.
La sauvegarde consiste à combiner une sauvegarde de niveau système de fichiers avec la sauvegarde des fichiers WAL.
La restauration consiste à restaurer les fichiers de la base puis de rejouer les fichiers WAL sauvegardés jusqu’à emmener la base à son état actuel.
Avantages :
- Il n’est pas nécessaire de disposer d’une sauvegarde des fichiers parfaitement cohérente comme point de départ. Toute incohérence dans la sauvegarde est corrigée par la ré-exécution des journaux
- Puisqu’une longue séquence de fichiers WAL peut être assemblée pour être rejouée, une sauvegarde continue est obtenue en continuant simplement à archiver les fichiers WAL. C’est particulièrement intéressant pour les grosses bases de données dont une sauvegarde complète fréquente est difficilement réalisable.
- Les entrées WAL ne doivent pas obligatoirement être rejouées intégralement. La ré-exécution peut être stoppée en tout point, tout en garantissant une image cohérente de la base de données telle qu’elle était à ce moment-là. Ainsi, cette technique autorise la récupération d’un instantané (PITR) : il est possible de restaurer l’état de la base de données telle qu’elle était en tout point dans le temps depuis la dernière sauvegarde de base.
- Si la série de fichiers WAL est fournie en continu à une autre machine chargée avec le même fichier de sauvegarde de base, on obtient un système « de reprise intermédiaire » : à tout moment, la deuxième machine peut être montée et disposer d’une copie quasi-complète de la base de données.
Contraintes :
- approche plus complexe à administrer
- ne supporte que la restauration d’un cluster de bases de données complet, pas d’un sous-ensemble
- espace d’archivage important requis : si la sauvegarde de base est volumineuse et si le système est très utilisé, ce qui génère un grand volume de WAL à archiver.
La réplication
Dans une architecture maître-esclave, le transfert des données de base et des WAL (Log shipping) peut se configurer de 3 manières légèrement différentes :
- Warm Standby : les fichiers des transactions (WAL) archivés sont transférés du maître vers l’esclave par copie et rejoués, avec un retard d’un fichier WAL (16 MB) par rapport au maître. La perte éventuelle de données ne peut donc excéder 16 MB. Dans cette configuration, la base esclave n’est pas accessible.
- Hot Standby : le fonctionnement est identique au Warm Standby. La différence est que la base esclave est accessible en lecture seule.
- Streaming Replication : dans cette configuration, chaque transaction est transférée vers la machine esclave via le réseau, et rejouée, sans attendre que le fichier WAL soit complété. Ainsi, le RPO est quasiment nul (une transaction perdue au maximum dans une réplication asynchrone, 0 dans une réplication synchrone).
Tolérance à panne
La tolérance à panne (failover) est la capacité d’un système à maintenir un état de fonctionnement en dépit d’une défaillance logicielle ou matérielle. Elle est rendue possible par la réplication. Nous étudierons ici les moyens à mettre en oeuvre pour assurer une continuité de service en toutes circonstances.
Gestion du Failover avec repmgr
Une Architecture Maître/Esclave sert à gérer les situations de failover où la machine Esclave prend le relais en cas de défaillance de la machine Maître.
Pour ce faire, une réplication continue est instaurée entre les 2 machines de telle façon que les données des 2 machines soient quasiment identiques à chaque instant.
Pour pouvoir gérer en plus, la capacité de déclencher la bascule (le failover) automatiquement, il existe plusieurs outils dans l’écosystème PostgreSQL tels que repmgr. Celui-ci peut-être utilisé seul ou en conjonction avec d’autres outils de backup comme BARMAN (Backup and Recovery Manager for PostgreSQL) développé par 2ndQuadrant (https://www.2ndquadrant.com/) avec une licence GPL v3, dont la dernière version est la 2.5 du 23/10/2018 (http://www.pgbarman.org/).
Présentation de repmgr
repmgr est une suite d’outils open source développés par 2dQuadrant ( https://repmgr.org/docs/4.2/index.html) qui mettent en oeuvre la réplication native de PostgreSQL et qui permettent de disposer d’un serveur dédié aux opérations de lecture/écriture (Primary ou Maître) et d’un ou plusieurs serveurs en lecture seule (Standby ou Esclave). Deux principaux outils sont fournis :
- repmgr : outil en ligne de commandes pour les tâches d’administration :
- configuration des serveurs standby
- promotion d’un serveur standby en primary
- inverser les rôles des deux serveurs (switchover)
- afficher les statuts des serveurs
- repmgrd : deamon qui supervise l’état des serveurs et qui permet de :
- surveiller les performances
- opérer un failover quand il détecte la défaillance du primary en promouvant le standby
- émettre des notifications sur des événements qui peuvent survenir sur les serveurs à des outils qui vont déclencher des alertes (mail par exemple)
Architecture
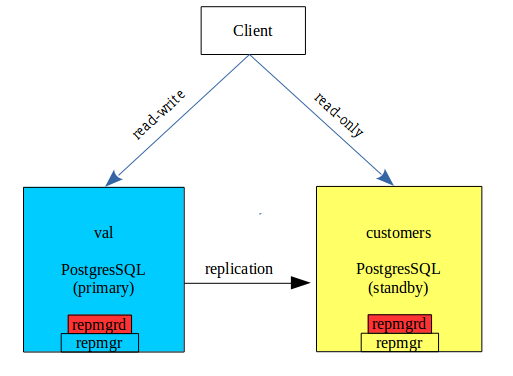
Pré-requis système
- Linux/Unix
- repmgr 4.x compatible avec PostgreSQL 9.3+
- La même version de PostgreSQL sur tous les serveurs du cluster
- repmgr doit être installé sur tous les serveurs du cluster, au moins dans la même version majeure*
- les connections entre serveurs doivent être ouvertes sur leurs ports respectifs
- les accès ssh par échange de clés publiques pour le user postgres de chacun des serveurs doivent être configurés.
Installation
L’installation se fait pour :
- RedHat/CentOS/Fedora à partir du repository yum de 2ndQuadrant
- Debian/Ubuntu à partir des repository APT de postgreSQL (http://apt.postgresql.org/) ou du repository APT de 2ndQuadrant (https://dl.2ndquadrant.com/default/release/site/)
Pour la version 10 de PostgrSQL :
sudo apt-get install postgresql-10-repmgr
- L’installation peut aussi se faire à partir des sources (cf. https://repmgr.org/docs/4.2/installation-source.html)
Configuration de PostgreSQL
Les exemples ci-dessous concernent une version 10.x de PostgreSQL
Ajuster les paramètres ci-dessous dans les fichiers de configuration des PostgreSQL (postgresql.conf) :
# Enable replication connections; set this figure to at least one more
# than the number of standbys which will connect to this server
# (note that repmgr will execute `pg_basebackup` in WAL streaming mode,
# which requires two free WAL senders)
max_wal_senders = 10
# Enable replication slots; set this figure to at least one more
# than the number of standbys which will connect to this server.
# Note that repmgr will only make use of replication slots if
# « use_replication_slots » is set to « true » in repmgr.conf
max_replication_slots = 3
# Ensure WAL files contain enough information to enable read-only queries
# on the standby.
#
# PostgreSQL 9.5 and earlier: one of ‘hot_standby’ or ‘logical’
# PostgreSQL 9.6 and later: one of ‘replica’ or ‘logical’
# (‘hot_standby’ will still be accepted as an alias for ‘replica’)
#
# See: https://www.postgresql.org/docs/current/static/runtime-config-wal.html#GUC-WAL-LEVEL
wal_level = replica
# Enable read-only queries on a standby
# (Note: this will be ignored on a primary but we recommend including
# it anyway)
hot_standby = on
# Enable WAL file archiving
archive_mode = on
# Set archive command to a script or application that will safely store
# you WALs in a secure place. /bin/true is an example of a command that
# ignores archiving. Use something more sensible.
archive_command = ‘/bin/true’
Création du user repmgr et du schéma repmgr
Le schéma repmgr sert à enregistrer les données de monitoring de repmgr. On y accède avec le user repmgr. Ils doivent être créés sur chacun des instances des serveurs :
sudo -i -u postgres
psql -p 5432
create role repmgr with password ‘password123’ ; alter role repmgr login ; alter role repmgr replication ; alter role repmgr superuser;
CREATE DATABASE repmgr OWNER repmgr;
Configuration de pg_hba.conf
L’objectif de cette configuration est de permettre au user repmgr de se connecter en mode replication :
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 195.154.39.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 195.154.39.0/24 trust
Vérifier que la base sur le serveur primaire est joignable à partir du serveur standby :
psql ‘host=195.154.39.62 user=repmgr dbname=repmgr connect_timeout=2’
Configuration de repmgr dans le noeud primaire
La configuration se fait dans le fichier /etc/repmgr.conf aux niveau du primaire (node_id=1, node_name=val) et du standby ((node_id=2, node_name=customers).
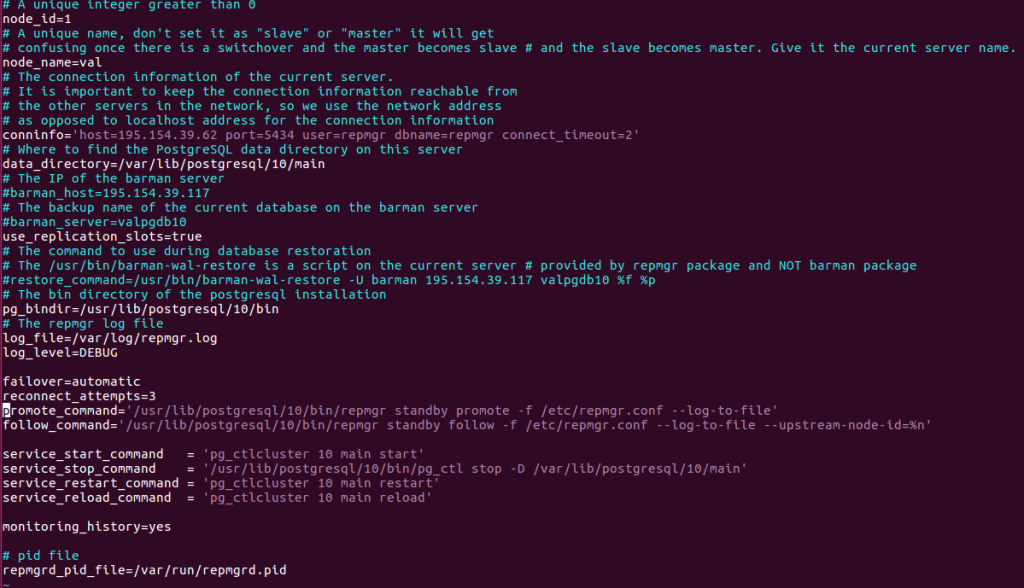
Remarques :
- Les paramètres indiqués ci-dessus sont les paramètres de base pour un fonctionnement standard de repmgr. On trouvera d’autres paramètres disponibles dans le fichier repmgr.conf.sample fourni dans la distribution.
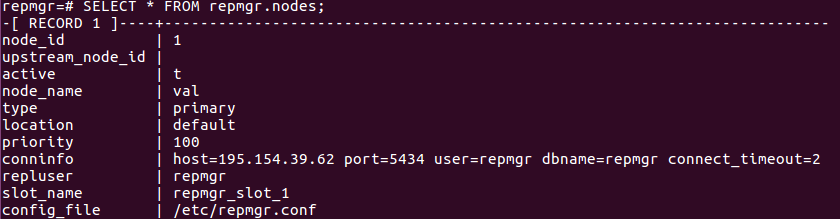
Enregistrement du serveur primaire
L’enregistrement du serveur primaire auprès de repmgr va créer les métadata dans le schéma repmgr et y initialisera un enregistrement correspondant au serveur primaire :
- Avec le user postgres , exécuter la commande suivante :
- $ repmgr -f /etc/repmgr.conf primary register
- Vérifier le statut du cluster avec la commande suivante :

Les metatda sont affichés avec la commande suivante :
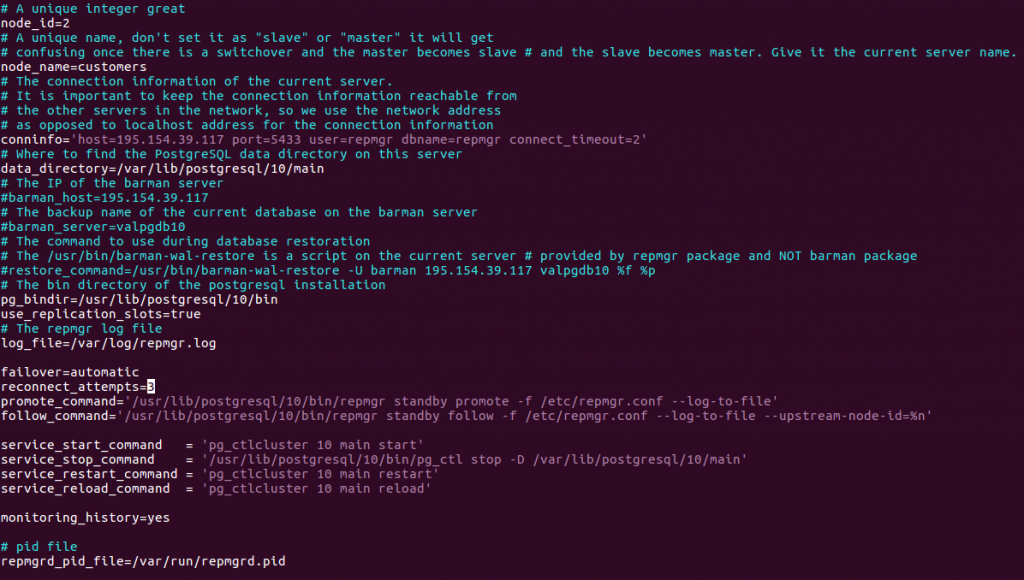
Configuration du serveur standby
Créer le fichier de configuration /etc/repmgr.conf, similaire à celui du primaire. Il diffère essentiellement par le n° et le nom du noeud ainsi que la chaîne de connexion conninfo :
Clonage du serveur standby
On exécutera la commande de clonage en dry-run pour s’assurer que toutes les conditions de succès sont satisfaites :
- postgres@customers:~$ repmgr -h 195.154.39.62 -U repmgr -d repmgr -p 5434 -f /etc/repmgr.conf -F standby clone –dry-run
Si pas de problème rapporté, exécuter la même commande sans l’option dry-run :
- postgres@customers:~$ repmgr -h 195.154.39.62 -U repmgr -d repmgr -p 5434 -f /etc/repmgr.conf -F standby clone
- Si le clonage s’est bien terminé , vérifier que la réplication se passe bien.
- Dans le serveur primaire, exécuter la commande suivante :
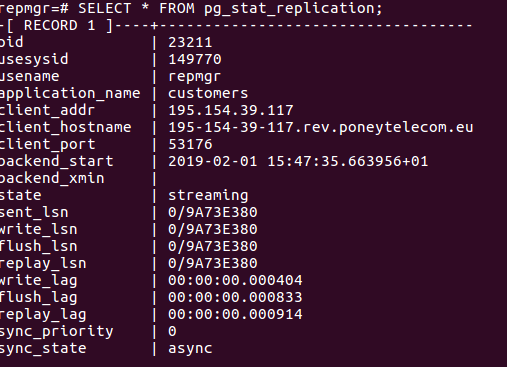
- Dans le serveur standby, exécuter la commande suivante :
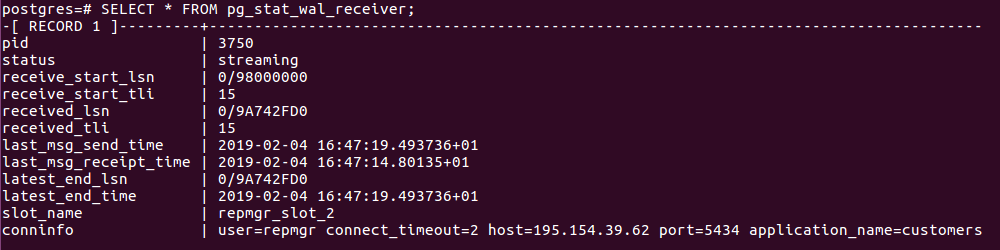
- Enregistrer le standby :
postgres@customers:~$ /usr/lib/postgresql/10/bin/repmgr standby register
- Vérifier que le standby est enregistré :

Vérifier que tout fonctionne
- Créer une table sur le maître :
CREATE TABLE rep_test (test varchar(40));
INSERT INTO rep_test VALUES (‘replique moi);
- Vérifier qu’elle est répliquée dans le standby:
SELECT * FROM rep_test;
Failover automatique avec repmgrd
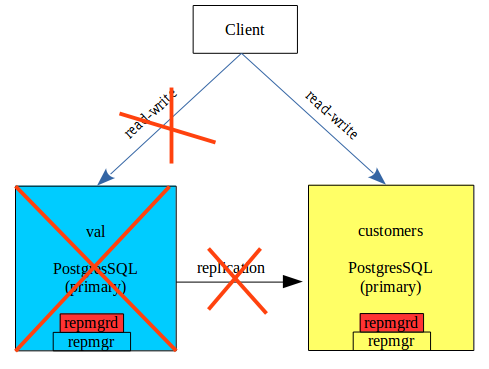
Dans le schéma ci-dessus, si val est indisponible , customers est promu en primary, et en mode read-write. Ce failover peut être exécuté manuellement avec 2 commandes de repmgr :
- Au niveau de customers : /usr/bin/repmgr standby promote -f /etc/repmgr.conf –log-to-file
- Au cas où il y aurait plusieurs serveurs standby, on exécute au niveau de chacun une commande de follow, qui leur indique le nouveau serveur maître :
/usr/bin/repmgr standby follow -f /etc/repmgr.conf –log-to-file –upstream-node-id=2
Le daemon repmgrd permet de surveiller l’état des serveurs du cluster et de déclencher automatiquement les 2 opérations décrites ci-dessus.
Configuration de repmgrd
- Pour utiliser repmgrd, inclure la librairie associée via la configuration de postgresql.conf :
shared_preload_libraries = ‘repmgr’
- ajouter dans /etc/repmgr.conf les lignes suivantes :
failover=automatic
promote_command=’/usr/lib/postgresql/10/bin/repmgr standby promote -f /etc/repmgr.conf –log-to-file’
follow_command=’/usr/lib/postgresql/10/bin/repmgr standby follow -f /etc/repmgr.conf –log-to-file –upstream-node-id=%n’
monitoring_history=yes
- Si repmgr a été installé à partir des packages de Debian/Ubuntu, il faudra configurer pour que repmgrd tourne en daemon, via le fichier /etc/default/repmgrd , dont le contenu est le suivant :
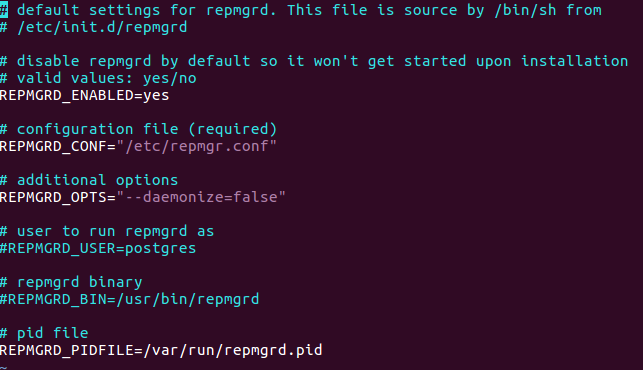
Démarrage de repmgrd
Pour démarrer repmgrd, exécuter la commande suivante sur chacun des serveurs, en tant que postgres :
/usr/lib/postgresql/10/bin/repmgrd -f /etc/repmgr.conf
Vérification du fonctionnement du failover
En considérant l’architecture à 2 serveurs ci-dessus , effectuer les opérations suivantes :
- Statut du départ :

- Après le démarrage de repmgrd sur les 2 serveurs, vérifier sur leurs logs respectifs qu’ils sont bien actifs
- Arrêter le serveur primaire :
/usr/lib/postgresql/10/bin/pg_ctl stop -D /var/lib/postgresql/10/main
- Vérifier de nouveau le statut du cluster :

On remarque que le noeud 2 est devenu primaire.
- Une fois, val “réparé”, le retour à la situation initiale s’effectue en 2 temps : d’abord mettre val comme standby du primaire customers puis faire un switchover sur val pour qu’il redevienne primaire et customers redevient standby :
- Cloner val à partir de customers et l’enregistrer comme standby :
postgres@val$ /usr/lib/postgresql/10/bin/repmgr -h 195.154.39.117 -p 5433 -U repmgr -d repmgr -f /etc/repmgr.conf standby clone –force
- Redémarrer val :
postgres@val$ pg_ctlcluster 10 main start
- enregistrer val en standby :
postgres@val$ /usr/lib/postgresql/10/bin/repmgr standby register –force
- Vérifier l’état du cluster :

On constate que le cluster fonctionne avec customers comme primaire et val comme standby.
Pour inverser les rôles, on fait un switchover sur le standby :
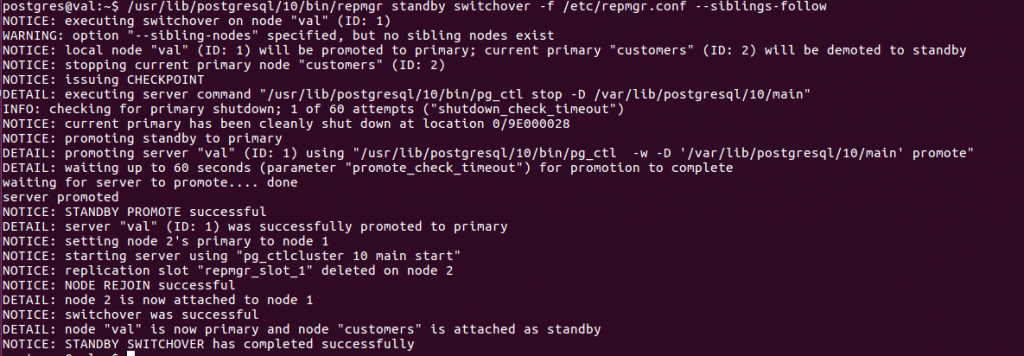
- Vérifier l’état du cluster

Remarque : le switchover agit sur le standby et sur les autres serveurs pour qu’ils soient avertis du nouveau primaire.
Conclusion
Ce post a permis d’exposer pas à pas les étapes pour configurer une HA sur un cluster à 2 noeuds, en mode primaire/standby. Pour ce faire, on a mis en oeuvre une streaming réplication avec repmgr et un monitoring des 2 noeuds avec le daemon associé à repmgr, ce qui permet de déclencher le failover automatique en cas de défaillance du noeud primaire. Le retour à la configuration initiale, après réparation de la défaillance, est réalisé avec un switchover. Le protocole de streamaing réplication permet de minimiser le RPO car il permet de rejouer les transactions au fil de l’eau au niveau du standby. Pour minimiser le RTO, il faut ajuster la fréquence des backup de base en fonction de la volumétrie des transactions.
La configuration qui a été présentée ici, peut être renforcée par un système de load balancing par un outil tiers dans le cas général , style pgpool-II ( http://www.pgpool.net ) ou par le driver jdbc si on est dans l’écosystème java.